

Enhancing Talent Acquisition: Early Placement Prediction with Machine Learning


Introduction:
In the competitive talent acquisition landscape, identifying the right candidates for internship placements is paramount for fostering organizational growth and innovation.
At our tech company, we recognize the importance of leveraging data-driven insights to streamline our recruitment processes. Today, we'll explore how early placement prediction, powered by machine learning algorithms, is revolutionizing our approach to talent acquisition.
Understanding Early Placement Prediction:
Early placement prediction involves utilizing historical data and machine learning algorithms to forecast the suitability of candidates for specific roles or programs. By analyzing a diverse range of factors such as academic performance, technical skills, and extracurricular activities, these algorithms generate predictions that inform our decision-making processes.
Example: Early Placement Prediction for Software Engineering Internships
Consider our objective of identifying promising candidates for software engineering internships. We gather data from past internship cohorts, including candidates' GPAs, technical assessment scores, project involvement, hackathon participation, programming language proficiency, and communication skills. This rich dataset serves as the foundation for training our machine-learning model.
Actual Dataset:
The dataset consists of the following features for each trainee:
GPA: Grade Point Average from university transcripts (numeric).
Technical Assessment Score: Score from a technical assessment evaluating programming proficiency (numeric).
Projects: Number of programming projects completed (numeric).
Hackathon Participation: A binary indicator (0 or 1) representing participation in hackathons.
Programming Languages: Proficiency in various programming languages (e.g., Python, Java, C++) rated on a scale of 1 to 5.
Communication Skills: Self-rated communication skills on a scale of 1 to 5.
Here's a snippet of our actual dataset:

Machine Learning Dataset for placement
Machine Learning Models:
We employ a logistic regression model to predict the likelihood of candidates being suitable for software engineering internships. This model is well-suited for binary classification tasks, where we aim to predict whether a candidate is suitable (1) or not suitable (0) for the internship.
Additionally, we explore other machine learning models such as decision trees, random forests, and support vector machines (SVMs). Decision trees are intuitive and easy to interpret, making them valuable for understanding the factors influencing predictions. Random forests combine multiple decision trees to improve prediction accuracy and handle complex datasets. SVMs are effective for separating data points in high-dimensional spaces and are suitable for cases with non-linear decision boundaries.
Prediction and Application:
Once trained, our machine learning models can predict the suitability of new candidates for software engineering internships based on their individual profiles. For instance, candidates with high GPAs, strong technical assessment scores, active project involvement, and proficiency in relevant programming languages are deemed highly suitable for the internship.
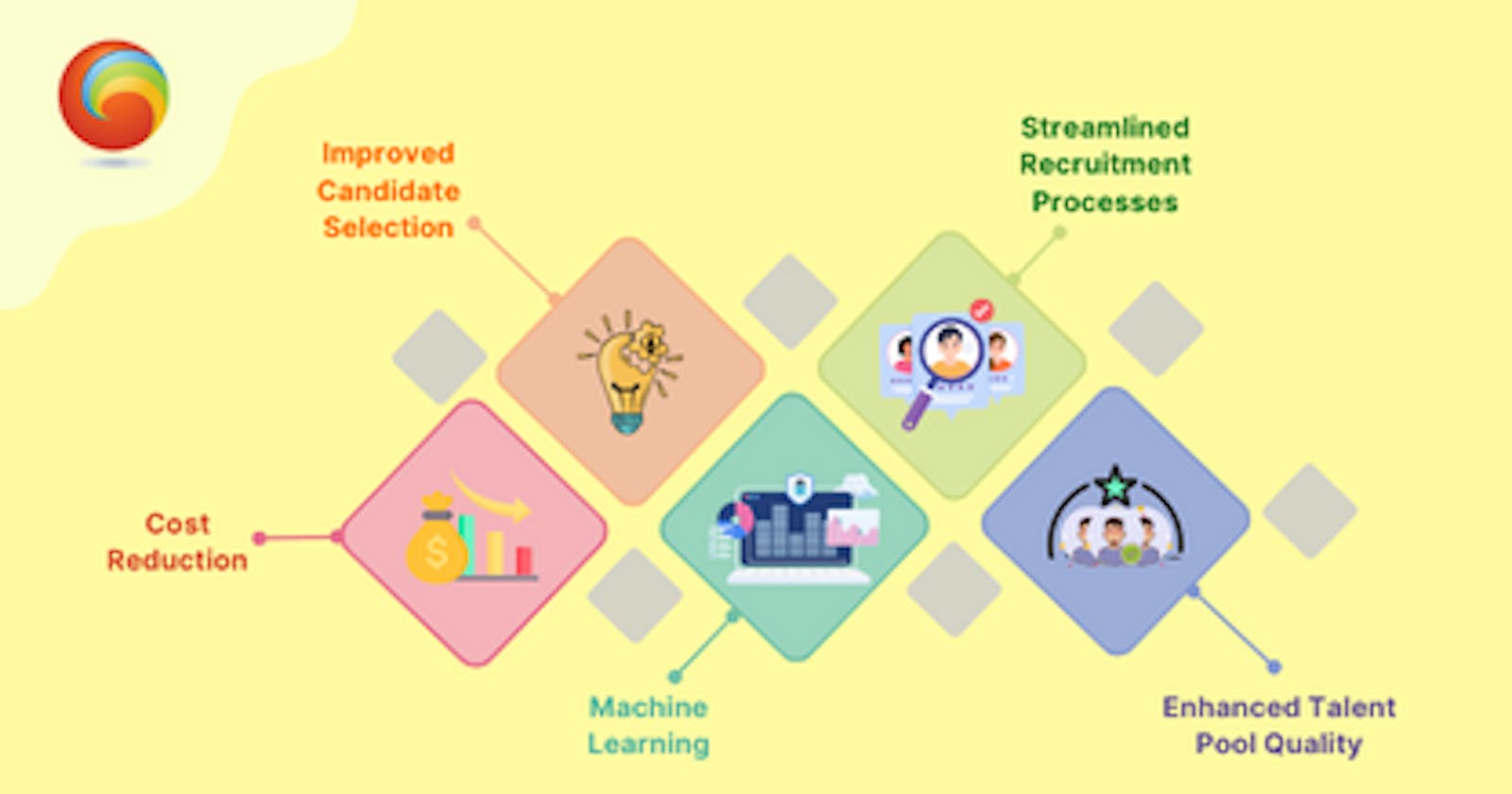
Benefits for the Company:
Early placement prediction offers several benefits for our company, including:
Streamlining talent acquisition processes and reducing recruitment costs.
Identifying high-potential candidates more efficiently leads to improved internship outcomes.
Enhancing the overall quality of our talent pool and fostering a culture of innovation and excellence.
Conclusion:
At our tech company, early placement prediction with machine learning is revolutionizing how we approach talent acquisition. By harnessing the power of data-driven insights and leveraging various machine learning models, we can identify and onboard top talent more effectively, driving our organization's success in the dynamic and competitive tech industry.
Frequently Asked Questions
How does early placement prediction impact recruitment costs?
- Early placement prediction can reduce recruitment costs by streamlining the selection process, allowing companies to focus resources more efficiently on candidates who are more likely to be successful in the role. This efficiency minimizes the need for extensive candidate screening and interviews, thus reducing overall recruitment expenditures.
How does the company ensure fairness in predictions?
- Fairness in predictions is often ensured through careful consideration of the features used in the machine learning models to avoid bias. Companies may employ techniques such as fairness-aware algorithms, bias mitigation strategies, and regular audits of the prediction process to identify and address any disparities or inequities.
Which machine learning models are utilized for prediction?
- The provided information mentions logistic regression as the primary model for early placement prediction. However, other models such as decision trees, random forests, and support vector machines (SVMs) are also explored for their suitability in predicting internship placements based on candidate profiles.
What benefits does early placement prediction offer?
Streamlining talent acquisition processes and reducing recruitment costs.
Identifying high-potential candidates more efficiently leads to improved internship outcomes.
Enhancing the overall quality of the talent pool and fostering a culture of innovation and excellence within the organization.